Disruptor 原理及实践
Disruptor 介绍
Disruptor 是英国外汇交易公司 LMAX 开发的一个高性能队列,研发的初衷是解决内存队列的延迟问题(在性能测试中发现竟然与 I/O 操作处于同样的数量级)。基于 Disruptor 开发的系统单线程能支撑每秒 600 万订单,2010 年在 QCon 演讲后,获得了业界关注。
Disruptor 区别于 Kafka、RabbitMQ 等消息队列,它是一个高性能的线程间异步通信的框架,即在同一个 JVM 进程中的多线程间消息传递。和 ArrayBlockingQueue 比较类似,但是它是一个有界无锁的高并发队列,如果项目中使用 ArrayBlockingQueue 在多线程之间传递消息,可以考虑是用 Disruptor 来代替。
内存消息队内介绍
常见的 Java 阻塞队列
| 名称 | 是否有界 | 是否加锁 | 数据结构 | 队列类型 |
|---|---|---|---|---|
| ArrayBlockingQueue | 有界 | 加锁 | 数组 | 阻塞 |
| LinkedBlockingQueue | 可选有界 | 加锁 | 链表 | 阻塞 |
| PriorityBlockingQueue | 无界 | 加锁 | 数组 | 阻塞 |
| DelayQueue | 无界 | 加锁 | 数组 | 阻塞 |
| LinkedTransferQueue | 无界 | 无锁 | 链表 | 阻塞 |
| LinkedBlockingDeque | 可选有界 | 有锁 | 链表 | 阻塞 |
在使用中,为了防止生产过快而消费不及时导致的内存溢出,或垃圾回收频繁导致的性能问题,一般会使用有界且数据结构为数组的阻塞队列,即:ArrayBlockingQueue。
但是,ArrayBlockingQueue 使用加锁的方式保证线程安全,在低延迟的场景中表现悲观,且存在伪共享的问题,因此结果不尽人意。
伪共享问题
cpu 内部的存储结构
现在的 CPU 都是多个 CPU 核心,如下图。为了提高访问效率,都有缓存行。每个核中都有 L1 Cache 和 L2 Cache,L3 Cache 则在多核之间共享。CPU 在执行运算时,首先从 L1 Cache 查找数据,找不到则以一次从 L2 Cache、L3 Cache 查找,如果还是没有,则会去内存中查找,路径越长,耗时越长,性能越低。当数据被修改后,通过主线通知其他 CPU 将读取的数据标记为失效状态,下次访问时从内存重新读取数据到 Cache
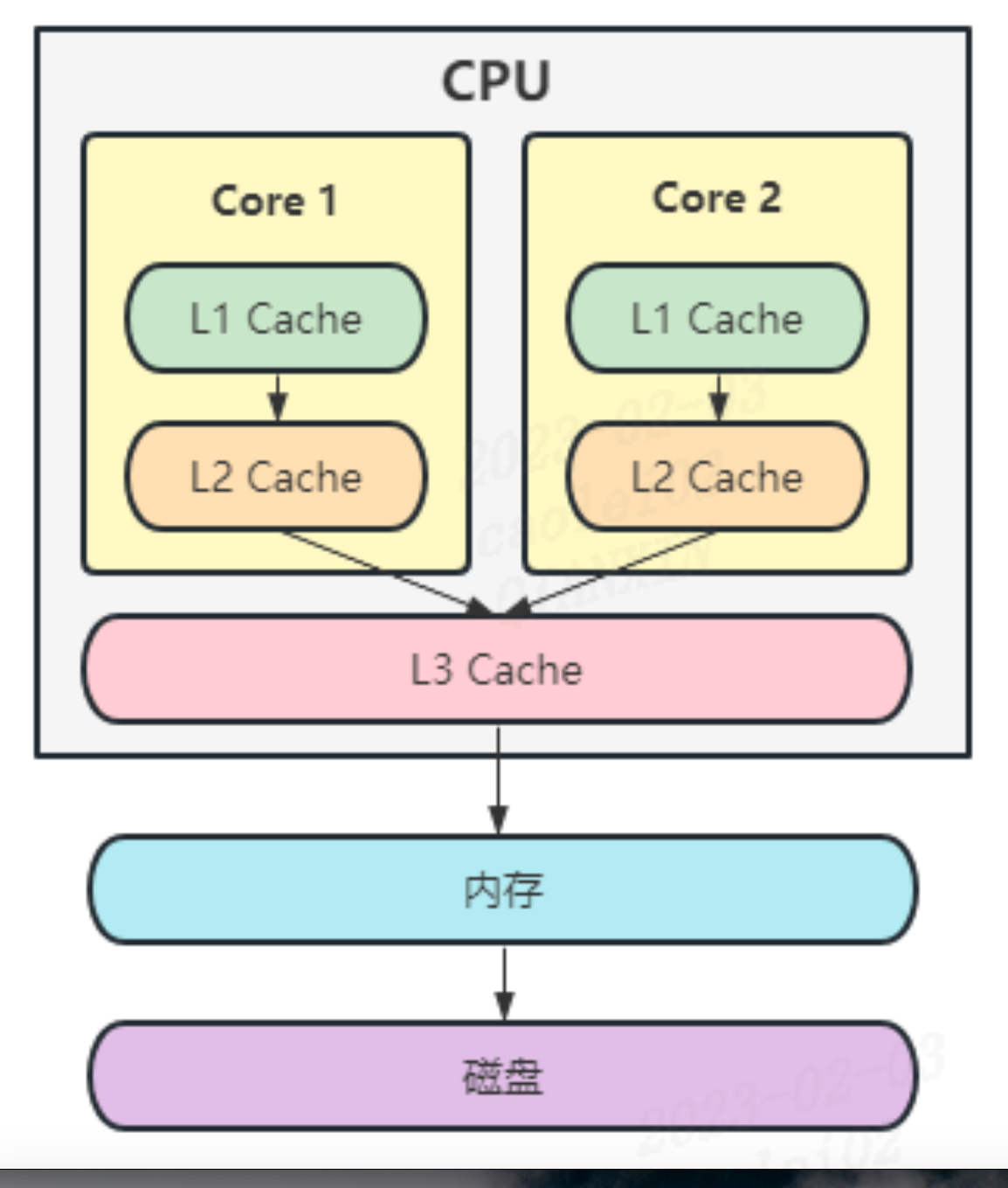
对于计算机的存储设备而言,除了 CPU 之外,外部还有内存和磁盘。存储容量越来越大,成本越来越大,但访问速度却越来越慢
缓存行
CPU 从内存中加载数据时,并不是一个字节一个字节的加载,而是一块一块的的加载数据,这样的一块称为:缓存行(Cache Line),即缓存行是 CPU 读取数据的最小单位。
CPU 的缓存行一般为 32 ~ 128 字节,常见的 CPU 缓存行为 64 字节。
# 查询 CPU 的 Cache Line 大小
cat /sys/devices/system/cpu/cpu0/cache/index0/coherency_line_size
对于数组而言,CPU 每次会加载数据中多个数据到 Cache 中。所以,如果按照物理内存地址分布的顺序去访问数据,Cache 命中率最高,从而减少从内存加载数据的次数,提高性能。
但对于单个变量而言,会存在 Cache 伪共享的问题。假设定义 Long 类型的变量 A,占用 8 个字节,则 CPU 每次从内存中读取数据时,会连同连续地址内的其余 7 个数据一并加载到 Cache 中。
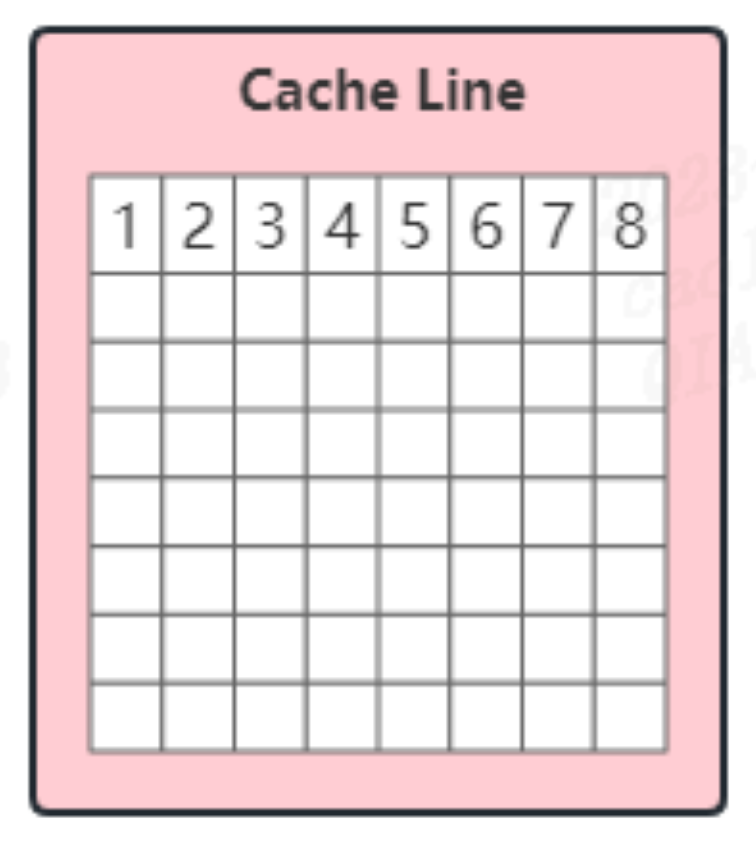
伪共享
多个 CPU 缓存遵循 MESI 协议。
假设,定义两个变量 A、B,线程 1 绑定 Core1,读取变量 A,线程 2 绑定 Core2,读取变量 B。
Core1 和 Core2 分别读取变量 A、B 到 Cache 中,但变量 A、B 在同一 Cache Line,因此,Core1 和 Core2 都会把数据 A、B 加载到 Cache 中
线程 1 通过 Core1 修改变量 A。首先通过主线发送消息给 Core2 将存放变量 A 的 Cache Line 标记为失效状态,然后将 Core1 中的 Cache Line 的状态标为已修改,并修改数据。
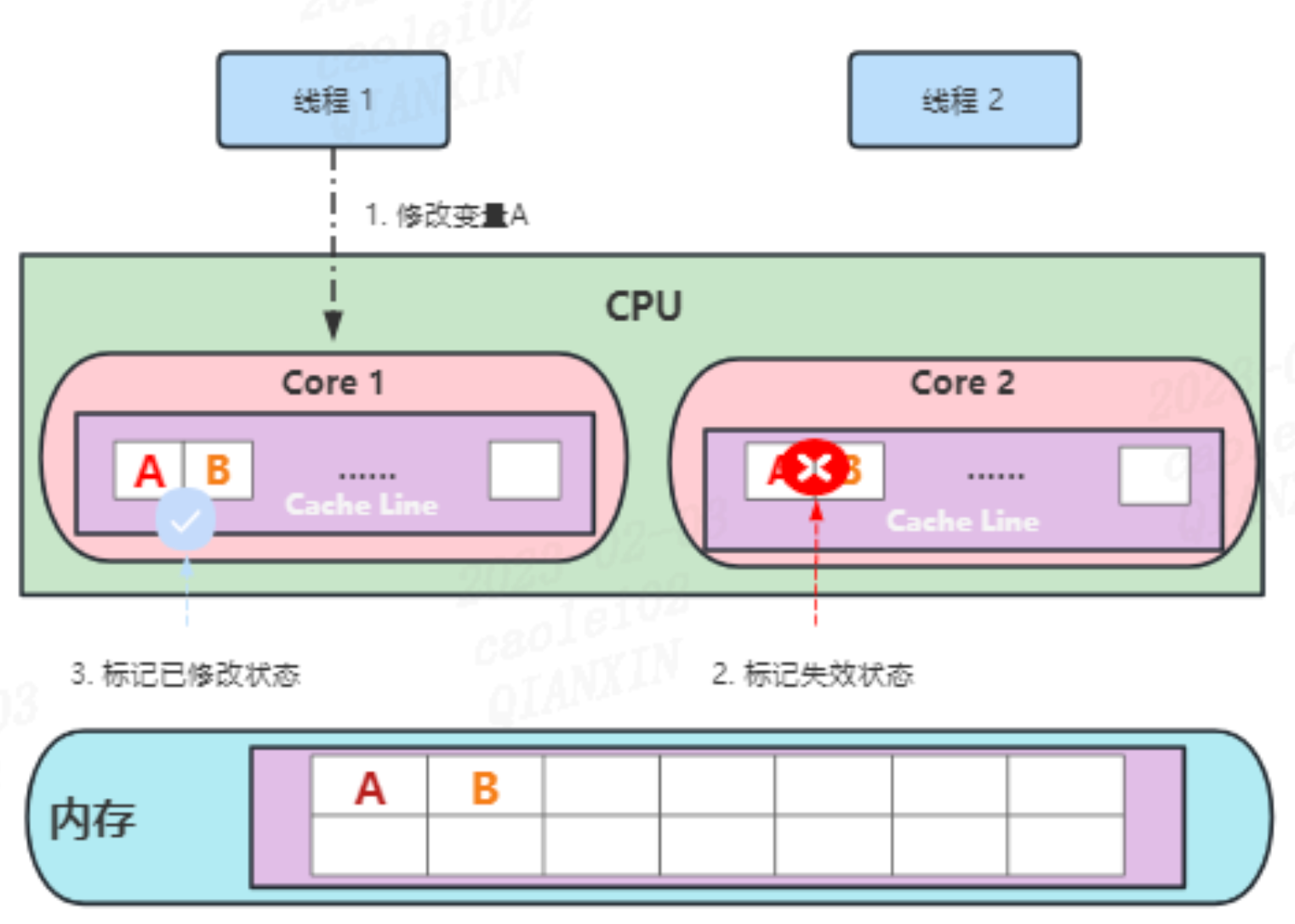
线程 2 修改变量 B 时,发现 Cache Line 的状态为失效,并且 Core1 中的 Cache Line 为已修改状态,则先把 Core1 中的变量 A、B 写回内存,然后从内存中重新读取变量 A、B。然后通过主线发送消息给 Core1 将存放变量 B 的 Cache Line 标记为失效状态,然后将 Core2 中的 Cache Line 的状态标为已修改,并修改数据。
如果线程 1、2 频繁交替修改变量 A、B,则会重复以上步骤,导致 Cache 没有意义。虽然变量 A、B 之间没有任何关系,但属于同一 Cache Line。
这种多个线程同时读写同一个 Cache Line 的不同变量而导致 CPU Cache 失效的现象称为伪共享(False Sharing)。
ArrayBlockingQueue 中的伪共享
查看 ArrayBlockingQueue 源码,有三个核心变量:
# 出队下标
/** items index for next take, poll, peek or remove */
int takeIndex;
# 入队下标
/** items index for next put, offer, or add */
int putIndex;
# 队列中元素数量
/** Number of elements in the queue */
int count;
这三个变量很容易放到同一 Cache Line,这也是影响 ArrayBlockingQueue 性能的重要原因之一。
Disruptor 原理
ArrayBlockingQueue 因为加锁和伪共享的问题影响性能,那 Disruptor 是如何避免这两个问题来提供性能的呢?主要表现在以下几个方面:
- 采用环形数组结构
- 采用 CAS 无锁方式
- 添加额外的信息避免伪共享
环形数组结构
环形数组(RingBuffer)结构是 Disruptor 的核心。官网对环形数据结构的剖析:Dissecting the Disruptor: What’s so special about a ring buffer
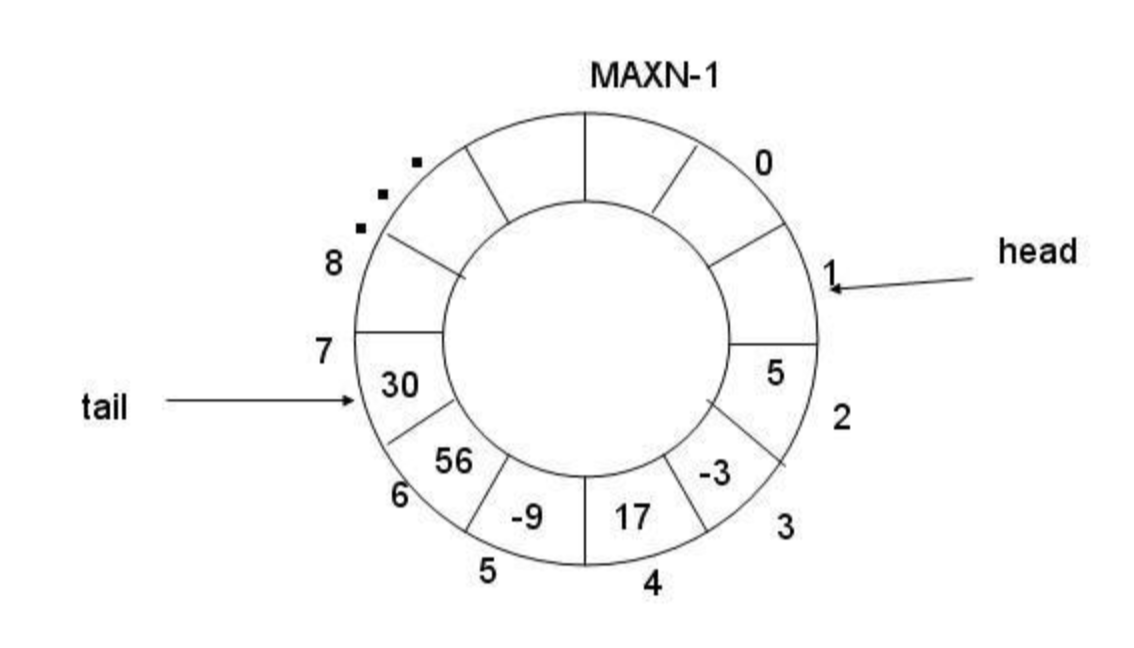
优势:
- 数组结构:当 CPU Cache 加载数据时,相邻的数据也会被加载到 Cache 中,避免 CPU 频繁从内存中获取数据。
- 避免 GC:实质还是一个普通的数组,当数据填满队列时(2^n - 1)时,再次添加数据会覆盖之前的数据。
- 位运算:数组大小必须为 2 的 n 次方,通过位运算提高效率。
CAS 无锁方式
Disruptor 与传统的队列不同,分为队首指针和队尾指针,而是只有一个游标器 Sequencer,它可以保证生产的消息不会覆盖还未消费的消息。Sequencer 分为两个实现类:SingleProducerSequencer 和 MultiProducerSequencer,即单生产者和多生产者。当单个生产者时,生产者每次从 RingBuffer 中获取下一个可以生产的位置,然后存放数据;消费者先获取最大的可消费的位置,再读取数据进行消费。当多个生产者时,每个生产者下通过 CAS 竞争获取可以生产的位置,然后存放数据;每个消费者都需要先获取最大可消费的下标,然后读取数据进行消费。
额外信息
RingBuffer 的下标是一个 volatile 变量,即不用加锁就能保证多线程安全,同时每个 long 类型的下标还会附带 7 个 long 的额外变量,避免伪共享的问题。
class LhsPadding
{
protected long p1, p2, p3, p4, p5, p6, p7;
}
class Value extends LhsPadding
{
protected volatile long value;
}
class RhsPadding extends Value
{
protected long p9, p10, p11, p12, p13, p14, p15;
}
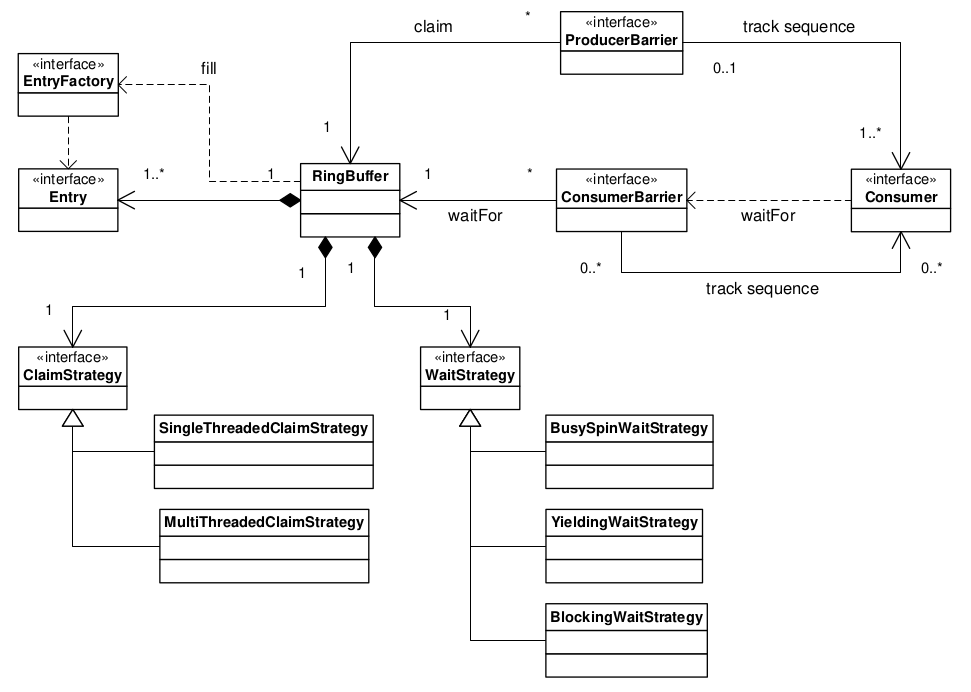
下面的类图描述了 Disruptor 框架中的核心关系
Disruptor 实践
配置依赖
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>cn.phixlin</groupId>
<artifactId>disrunptor-demo</artifactId>
<version>1.0-SNAPSHOT</version>
<parent>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-parent</artifactId>
<version>2.7.1</version>
<relativePath/>
</parent>
<properties>
<maven.compiler.source>8</maven.compiler.source>
<maven.compiler.target>8</maven.compiler.target>
</properties>
<dependencies>
<dependency>
<groupId>com.lmax</groupId>
<artifactId>disruptor</artifactId>
<version>3.4.4</version>
</dependency>
<dependency>
<groupId>org.projectlombok</groupId>
<artifactId>lombok</artifactId>
</dependency>
<dependency>
<groupId>com.alibaba.fastjson2</groupId>
<artifactId>fastjson2</artifactId>
<version>2.0.46</version>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-logging</artifactId>
</dependency>
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<scope>test</scope>
</dependency>
</dependencies>
<build>
<plugins>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-compiler-plugin</artifactId>
</plugin>
</plugins>
</build>
</project>
Disruptor 中的 2 种事件消费模式
在构建 Disruptor 的时候,明确指定了单生产者模式,那么消费者呢?有几个消费线程来处理消息?每个消息会被处理几次?
其核心在于调用 disruptor.handleEventsWith 设置消费者时,我们提供的 EventHandler 会被包装成 BatchEventProcessor, BatchEventProcessor 实现了 Runnable 接口
public final EventHandlerGroup<T> handleEventsWith(final EventHandler<? super T>... handlers)
{
return createEventProcessors(new Sequence[0], handlers);}
EventHandlerGroup<T> createEventProcessors(
final Sequence[] barrierSequences,
final EventHandler<? super T>[] eventHandlers){checkNotStarted();
final Sequence[] processorSequences = new Sequence[eventHandlers.length];
final SequenceBarrier barrier = ringBuffer.newBarrier(barrierSequences);
for (int i = 0, eventHandlersLength = eventHandlers.length; i < eventHandlersLength; i++)
{
final EventHandler<? super T> eventHandler = eventHandlers[i];
final BatchEventProcessor<T> batchEventProcessor =
new BatchEventProcessor<>(ringBuffer, barrier, eventHandler);
if (exceptionHandler != null){batchEventProcessor.setExceptionHandler(exceptionHandler);
}
consumerRepository.add(batchEventProcessor, eventHandler, barrier);
processorSequences[i] = batchEventProcessor.getSequence();}
updateGatingSequencesForNextInChain(barrierSequences, processorSequences);
return new EventHandlerGroup<>(this, consumerRepository, processorSequences);}
在 Disruptor 启动的时候,就会根据上述构造的消费者相关信息(ConsumerRepository)启动对应的线程去轮询消息并处理
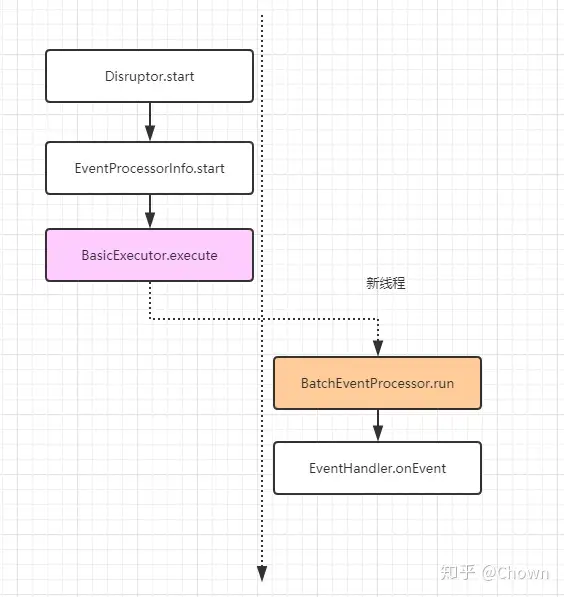
新线程就会一直从 RingBuffer 中轮询消息并调用对应的事件处理器处理。
通过上述的分析,我们可以知道消费者线程的个数取决于我们构造 Disruptor 时提供的 EventHandler 的个数。所以第一种实现多消费者模式的方法就是提供多个 EventHandler。
多个消费者各自处理事件(Multicast)
给 Disruptor 提供多个 EventHandler 就会开启多个消费者工作线程,每个消费者都会处理所有的事件,是一种多播模式。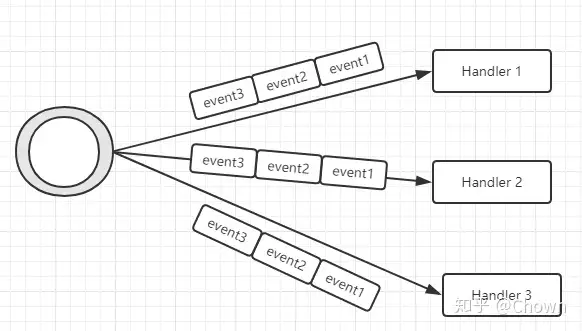
接下来看下源码为何如此?消费者想要获取到 RingBuffer 中的元素,就需要从 Sequnce 中取得可用的序列号,否则就会执行等待策略。前面已经说过, EventHandler 最终封装为 BatchEventProcessor,每个 BatchEventProcessor 在执行 EventHandler 相应逻辑之前都会先获取可用的序列号,因为每个 BatchEventProcessor 独立维护了一个 Sequence 对象,所以每个事件都会被所有的消费者处理一遍。
/**
* It is ok to have another thread rerun this method after a halt().
*
* @throws IllegalStateException if this object instance is already running in a thread
*/
@Override
public void run()
{
if (running.compareAndSet(IDLE, RUNNING))
{sequenceBarrier.clearAlert();
notifyStart();
try
{
if (running.get() == RUNNING){processEvents();
}
}
finally
{notifyShutdown();
running.set(IDLE);
}
}
else
{
// This is a little bit of guess work. The running state could of changed to HALTED by
// this point. However, Java does not have compareAndExchange which is the only way
// to get it exactly correct.
if (running.get() == RUNNING)
{
throw new IllegalStateException("Thread is already running");}
else
{earlyExit();
}
}
}
private void processEvents()
{
T event = null;
long nextSequence = sequence.get() + 1L;
while (true)
{
try
{
final long availableSequence = sequenceBarrier.waitFor(nextSequence);
if (batchStartAware != null)
{
batchStartAware.onBatchStart(availableSequence - nextSequence + 1);}
while (nextSequence <= availableSequence)
{event = dataProvider.get(nextSequence);
eventHandler.onEvent(event, nextSequence, nextSequence == availableSequence);
nextSequence++;
}
sequence.set(availableSequence);
}
catch (final TimeoutException e){notifyTimeout(sequence.get());
}
catch (final AlertException ex)
{
if (running.get() != RUNNING)
{
break;
}
}
catch (final Throwable ex)
{handleEventException(ex, nextSequence, event);
sequence.set(nextSequence);
nextSequence++;
}
}
}
多个消费者合作处理一批事件
上面的方式是每个 Consumer 都会处理相同的消息,可以联系 EventBus,Kafka 里面的 ConsumerGroup。那么如果想多个 Consumer 协作处理一批消息呢?此时可以利用 Disruptor 的 WorkPool 支持,我们定制相应的线程池(Executor)来处理 EventWorker 任务。
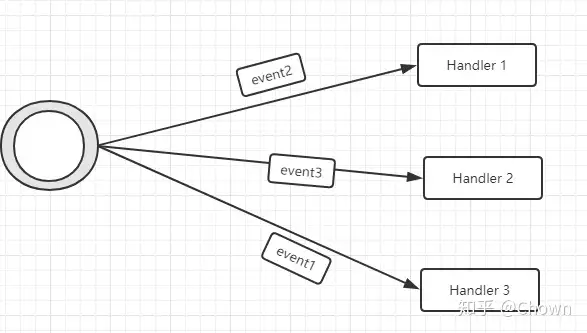
使用这种模式的一种场景是处理每个事件比较耗时,开启多个线程来加快处理。
RingBuffer<LogEvent> ringBuffer = RingBuffer.create(ProducerType.SINGLE, new LogEventFactory(), bufferSize,
new YieldingWaitStrategy());
SequenceBarrier barriers = ringBuffer.newBarrier();
WorkerPool<LogEvent> workerPool = new WorkerPool<LogEvent>(ringBuffer, barriers, null, consumers);
ringBuffer.addGatingSequences(workerPool.getWorkerSequences());
workerPool.start(executor);
接下来分析怎么做到一个事件只处理一次的。在使用 WorkPool 时,我们提供的事件处理器最终会被封装为 WorkProcessor,里面的 run 方法便揭示了原因:所有的消费者都是从同一个 Sequnce 中取可用的序列号
调用 disruptor.handleEventsWithWorkerPool 时,我们提供的 WorkHandler 会被包装成 WorkProcessor
@Override
public void run()
{
if (!running.compareAndSet(false, true))
{
throw new IllegalStateException("Thread is already running");}
sequenceBarrier.clearAlert();
notifyStart();
boolean processedSequence = true;
long cachedAvailableSequence = Long.MIN_VALUE;
long nextSequence = sequence.get();
T event = null;
while (true)
{
try
{
// if previous sequence was processed - fetch the next sequence and set
// that we have successfully processed the previous sequence
// typically, this will be true
// this prevents the sequence getting too far forward if an exception
// is thrown from the WorkHandler
if (processedSequence)
{
processedSequence = false;
do
{nextSequence = workSequence.get() + 1L;
sequence.set(nextSequence - 1L);}
while (!workSequence.compareAndSet(nextSequence - 1L, nextSequence));}
if (cachedAvailableSequence >= nextSequence)
{event = ringBuffer.get(nextSequence);
workHandler.onEvent(event);
processedSequence = true;
}
else
{cachedAvailableSequence = sequenceBarrier.waitFor(nextSequence);
}
}
catch (final TimeoutException e){notifyTimeout(sequence.get());
}
catch (final AlertException ex)
{
if (!running.get())
{
break;
}
}
catch (final Throwable ex)
{
// handle, mark as processed, unless the exception handler threw an exception
exceptionHandler.handleEventException(ex, nextSequence, event);
processedSequence = true;
}
}
notifyShutdown();
running.set(false);}
在使用 WorkPool 的时候务必要保证一个 Consumer 要对应一个线程,否则当 RingBuffer 满的时候,Producer 和 Consumer 都会阻塞
推荐使用的是提供 ThreadFactory 形式的构造器,后续会根据事件处理器的个数来新增对应的线程
public Disruptor(
final EventFactory<T> eventFactory,
final int ringBufferSize,
final ThreadFactory threadFactory,
final ProducerType producerType,
final WaitStrategy waitStrategy)
{
this(RingBuffer.create(producerType, eventFactory, ringBufferSize, waitStrategy),
new BasicExecutor(threadFactory));
}
代码示例
消息模型
用于在 Disruptor 之间传递消息
@Data
@AllArgsConstructor
@NoArgsConstructor
public class Messages {
private Object data;
@Override
public String toString() {
return JSON.toJSONString(data);
}
}
生产者
@RequiredArgsConstructor
public class Producer {
private final Disruptor disruptor;
/**
* 发送数据
*
* @param data 数据
*/
public void send(Object data) {RingBuffer<Messages> ringBuffer = disruptor.getRingBuffer();
// 获取可以生成的位置
long next = ringBuffer.next();
Messages mes = ringBuffer.get(next);
mes.setData(data);
ringBuffer.publish(next);
}
}
消费者
分组消费模式消费者
@RequiredArgsConstructor
@Slf4j
public class GroupConsumer implements WorkHandler<Messages> {
/**
* 消费者编号
*/
private final Integer number;
@Override
public void onEvent(Messages event) throws Exception {
Thread.sleep(1000);
log.info("Group Consumer number: {}, message: {}", number, event);}
}
重复模式消费者
@RequiredArgsConstructor
@Slf4j
public class RepeatConsumer implements EventHandler<Messages> {
private final Integer number;
@Override
public void onEvent(Messages event, long sequence, boolean endOfBatch) throws Exception {
Thread.sleep(2000);
log.info("Repeat Consumer number: {}, message: {}, curr sequence: {}, is end: {}", number, event, sequence, endOfBatch);}
}java
通用消费模式消费者
@Slf4j
@RequiredArgsConstructor
public class Consumer implements WorkHandler<Messages>, EventHandler<Messages> {
private final String desc;
/**
* 重复消费:每个消费者重复消费生产者生产的数据
*
* @param event 消息
* @param sequence 当前序列号
* @param endOfBatch 批次结束标识(常用于将多个消费着的数据依次组合到最后一个消费者统一处理)
*/
@Override
public void onEvent(Messages event, long sequence, boolean endOfBatch) throws Exception {
this.onEvent(event);
}
/**
* 分组消费:每个生产者生产的数据只能被一个消费者消费
*
* @param event 消息
* @throws Exception
*/
@Override
public void onEvent(Messages event) throws Exception {
Thread.sleep(2000);
log.info("Group Consumer describe: {}, message: {}", desc, event);}
}
单元测试
- 多个消费者各自处理事件 (多播模型) - 实现 EventHandler
public class RepeatConsumerTest {
private Disruptor<Messages> disruptor;
@Before
public void init(){
RepeatConsumer a = new RepeatConsumer(1);
RepeatConsumer b = new RepeatConsumer(2);
disruptor = new Disruptor<Messages>(Messages::new,1024, Executors.defaultThreadFactory());
EventHandlerGroup<Messages> messagesEventHandlerGroup = disruptor.handleEventsWith(a, b);
RingBuffer<Messages> start = disruptor.start();}
@After
public void close(){disruptor.shutdown();
}
@Test
public void test(){
Producer producer = new Producer(disruptor);
Arrays.asList("aaa","bbb","ccc").forEach(f -> producer.send(f));
}
}
- 多个消费者合作处理一批事件 (分组模型) - 实现 WorkHandler
public class GroupConsumerTest {
private Disruptor<Messages> disruptor;
@Before
public void init() {
GroupConsumer a = new GroupConsumer(1);
GroupConsumer b = new GroupConsumer(2);
disruptor = new Disruptor<>(Messages::new, 1024, Executors.defaultThreadFactory());
EventHandlerGroup<Messages> messagesEventHandlerGroup = disruptor.handleEventsWithWorkerPool(a, b);
disruptor.start();}
@After
public void close() {disruptor.shutdown();
}
/**
* 每个生产者生产的数据只能被一个消费者消费
*/
@Test
public void test() {
Producer producer = new Producer(disruptor);
Producer producer1 = new Producer(disruptor);
Arrays.asList("aaa", "bbb", "ccc", "ddd", "eee").forEach(f -> {producer.send(f);
producer1.send(f+"_2");});
}
}
- 复合消费模型 - 同时实现 EventHandler 和 WorkHandler
public class MultiConsumersTest {
/**
* 测试链路模式
* <p>
* p => a -> b -> c
* </p>
*/
@Test
public void testChain() throws InterruptedException {
Consumer a = new Consumer("a");
Consumer b = new Consumer("b");
Consumer c = new Consumer("c");
Disruptor<Messages> disruptor = new Disruptor<>(Messages::new, 1024, Executors.defaultThreadFactory());
EventHandlerGroup<Messages> then = disruptor.handleEventsWith(a).then(b).then(c);
disruptor.start();
Producer producer = new Producer(disruptor);
producer.send("http://bing.com");
Thread.sleep(1000);
disruptor.shutdown();}
/**
* 测试钻石模式
* <p>
* a
* ↗ ↘
* p => c
* ↘ ↗
* b
* </p>
*/
@SneakyThrows
@Test
public void testDiamond() {
Consumer a = new Consumer("a");
Consumer b = new Consumer("b");
Consumer c = new Consumer("c");
@Cleanup("shutdown") Disruptor<Messages> disruptor = new Disruptor<>(Messages::new, 1024, Executors.defaultThreadFactory());
EventHandlerGroup<Messages> then = disruptor.handleEventsWithWorkerPool(a, b).handleEventsWith(c);
RingBuffer<Messages> start = disruptor.start();
Producer producer = new Producer(disruptor);
producer.send("http://bing.com");
producer.send("http://baidu.com");
producer.send("http://phixlin.cn");}
}